
We’re all very familiar with the benefits of real-time data processing and decisioning, for businesses and consumers alike. The ability for enterprises to respond quickly and automatically to our actions mean that we see more relevant information (even in the form of advertisements) and are able to serve ourselves more capably than ever before. And when we do need help, we can chat to a live service agent – or indeed a chatbot – at our own convenience.
All of these transactions create events that feed into an enterprise’s systems, events from which insights may be derived and experiences tailored. These data feeds are only becoming larger and more diverse as businesses start receiving information from the millions of devices and connected sensors being integrated into our lives. Companies know there’ll be fascinating, actionable insights in there, but to identify and respond to them in a timely manner is a challenge.
The data is going to have to be processed and decisioned upon as quickly and smartly as possible.
Think of your systems as a railroad.
The track that does the transporting must be efficiently laid, well maintained, with smooth joins between sections. These are the processing components. The signals that do the routing are vital to keeping the flow of traffic going; they must be intelligently programmed, and they must be adaptable when changes are needed. These are the components that do the decisioning. Both sets of components are critical to delivering an effective real-time system. It’s when both are working efficiently that value from real-time data is to be found.
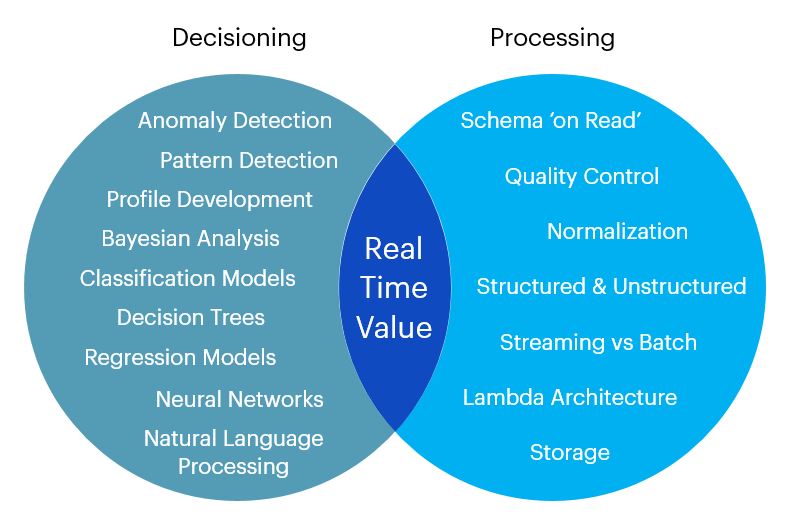
How real-time decisioning and processing combine to create value
At LigaData, we’ve worked with numerous enterprises to upgrade their systems to handle a growing inflow of real-time data. While every case is different, there are some common considerations:
- Ring-fence legacy systems. It’s easy to get paralyzed by the work needed to upgrade or migrate existing platforms. Instead, draw a line around them, and incorporate them within your wider data processing platform through well-defined interfaces.
- Apply the extended lambda architecture. This configuration of decisioning, speed and batch processing layers builds upon and beyond traditional real-time decisioning and lambda architectures, enabling immediate processing and decisioning based upon real-time streaming and historical data, as well as a feed of continuous refinement.
- Develop models in an environment as close as possible to the operational environment. Delays often occur in the time between the creation of algorithms developed in an analyst’s or data scientist’s analytical environment and putting them into practice. These delays are often due to the need to translate data processing pipelines and models to a form that works in the operating environment. Some delays are unavoidable, often due to mandated regulatory controls. However, the technical barriers to operationalization should be reduced to a minimum, ideally with plug-n-play compatibility between the analytical and operational environments.
- Be picky about your data. The more there is, the more resources it’ll absorb, no matter the level of automation or machine learning incorporated in your pipeline. Remind yourself to step back from time to time and consider what insights your business really values, which you have the business capacity to react to, and what data these insights really require. Sometimes, less really is more.
To read more about some of the work LigaData has done, please take a look at our white papers on extended lambda architecture for continuous decisioning, and using continuous decisioning to detect fraud.
And if you’d like to discuss how real-time processing and decisioning can benefit your enterprise, we’d love to hear from you at info@ligadata.com.
This article was first published by LigaData on 8 May 2017, and reviewed for relevancy in 2018. We think it still has validity.

