


While not a brand-new term, Data Lakehouses are only starting to catch fire in the Technology, Media, and Telecom (TMT) industry.
At LigaData we are actively implementing this novel approach to data structuring with our clients. In this blog, I’ll describe what we are doing to give users of Data Lakes with legacy Data Warehouses built on top, the ability to perform ACID transactions using a new architectural pattern – a Lakehouse. This term far first coined by James Dixon who was chief technology officer at Pentaho at the time.
When I say Lakehouse, I’m referring to a structure based on open architecture with directly accessible data formats, such as Parquet. Specifically, it is a storage structure (physical and meta data) built to combine the architecture of a Data Warehouse, with scalability and flexibility of a data lake (I’ll go into more details in a moment). With a Lakehouse we can provide comprehensive support for AI and Analytics use cases, and offer rapid performance to retrieve data directly from the data lake. Lakehouses are the solution to a number of serious concerns about Data Warehouses built on top of Data Lakes, including reliability and data quality, cost of ownership, and support of standard Telco data models.
The Evolution of Business Intelligence
Let’s start with a bit of ancient history. For those who are not old enough to remember the last Dallas Cowboys Superbowl appearance – that’s how far back we’re going (sorry this is how I measure time).
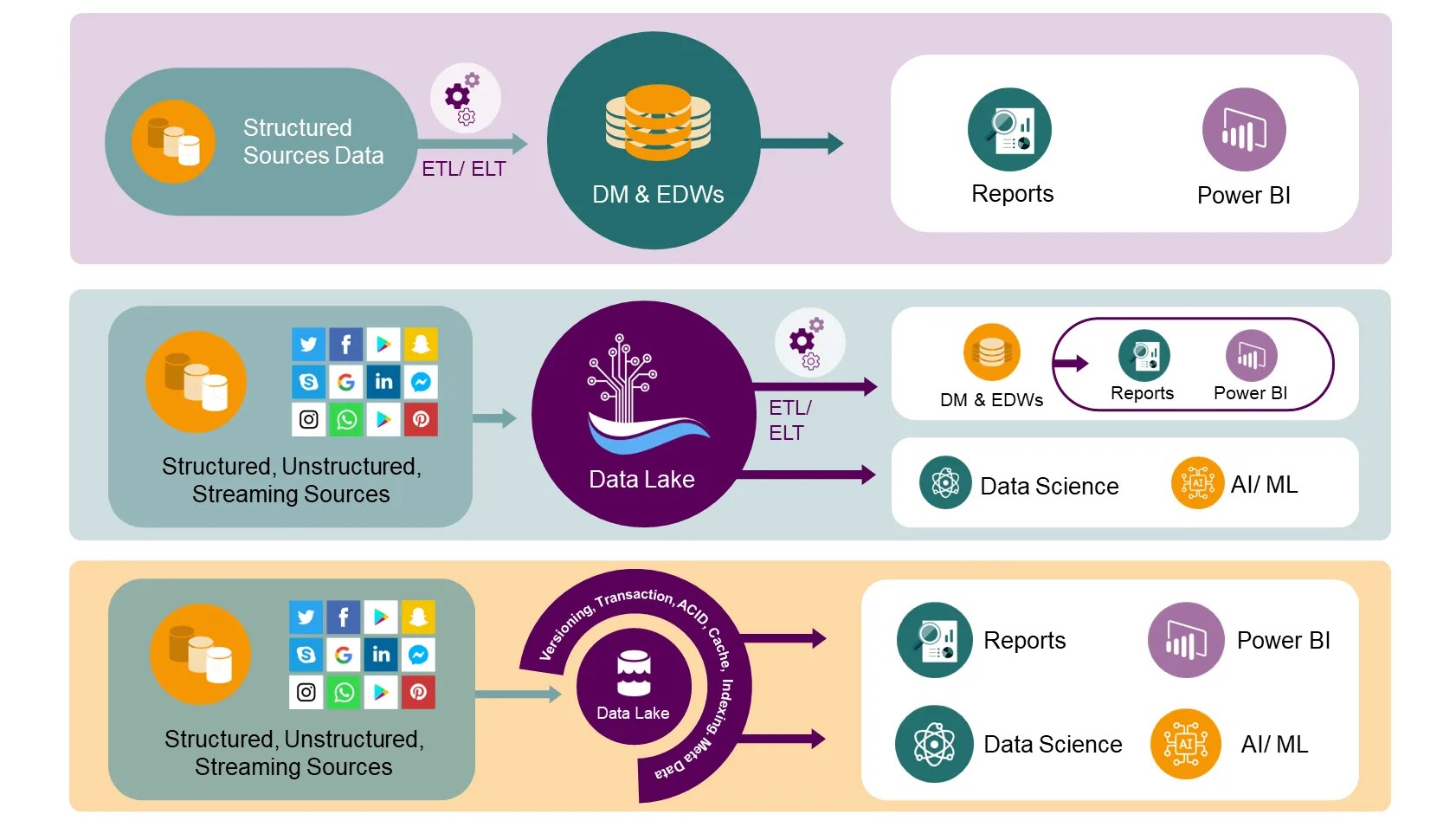
Figure 1: Data Lakes have made it possible to integrate all kinds of Telco data including structured and unstructured data but at the cost of ACID transactions. For some, this in an important issue to be resolved.
As we all know, Data Warehousing began by providing Businesses with nicely organized data from which insights were gained from Operations Support System (OSS) data. This was done by collecting data from operational sources into centralized datamarts, which were then used for decision support and BI. Data in these datamarts, later to be integrated to form the Enterprise Data Warehouse (EDW), followed a schema-on-write approach, ensuring the data model was optimized for BI queries. Many effective Telco datamarts were developed at this time.
Somewhere back at the turn of the millennium, EDWs started to face important challenges.
Firstly, data, particularly Telco data, did not conform to nice polite structures that fit an Relational Database Management System (RDBMS) database. A need arose for Telcos to understand the full 360-degree profile of customers and required new data formats, such as subscriber documents for KYC, subscriber pictures and social media streams. Eventually music and often videos would be required. In other words, unstructured data. This unstructured data could not be stored and queried at all.
Secondly, data volumes were starting to geometrically increase at the same time data was needed in real-time.
Finally, traditional Data Warehouses had to have expensive appliances that sat on-prem and could not be easily scaled. Most of these requirements couldn’t be met by EDWs or if possible were prohibitively expensive.
This is when the concept of a Data Lake evolved. Data Lakes are very efficient at storing vast amounts of unstructured data and at a low cost in comparison to other structures. With a Data Lake, companies could integrate data in real-time, process it, and dump it in the Data Lake without having to go through a lot of ETL/ELT. Which, as we know, causes the bulk of data quality issues, latencies, and resource utilization complications. The Data Lake was a schema-on-read architecture that enabled storing all types of data quickly and at a low cost. However, there were drawbacks. This whole methodology started with Apache Hadoop and using the Hadoop File System (HDFS) for cheap storage – Big Data. By the way… our CEO, Bassel Ojjeh, led the group at Yahoo! where Big Data was developed. For historical accuracy, Big Data was the outcome of two companies battling to amass as much data as possible to win the Search Engine war (we know who won it). Google and Yahoo. Several new technologies came out at that time; Google with Big Table, Yahoo with Hadoop and Columnar storage. Columnar storage was developed by our CTIO Krishna Uppala’s company which also ended up being purchased by Yahoo! (Yes. I know, an egregious self-serving plug).
Anyway, since the Data Lake integrates raw data from many sources (in Telcos often 100+) and does not modify the data format (schema-on-read), we get raw data. With so many sources it takes a professional data scientist to retrieve data. Not only a data scientist, but those who already know the data and how it should be organized. A rare commodity and a step away from self-service.
With the Data Lake itself, most Business users are left out in the cold (or lake) without a semantic layer. No easily available ACID, no more indexes or primary and foreign Key. For this reason, many Telco’s started writing ETL/ELT to extract data from the Data Lake into specific datamarts. Let me name them “Data Warehouses”.
As a reminder; ACID stands for four traits of database transactions:
- Atomicity: an operation either succeeds completely or fails, it does not leave partial data,
- Consistency: once an application performs an operation the results of that operation are visible to it in every subsequent operation,
- Isolation: an incomplete operation by one user does not cause unexpected side effects for other users
- Durability: once an operation is complete it will be preserved even in the face of machine or system failure.
Traditionally, Data Lakes have managed data as a group of files in a semi-structured format (again Parquet for example, because we use this format). This all but disqualified offering many management features that simplify ETL/ELT in Data Warehouses, such as transactions, and versioning. Albeit several systems such as Apache Iceberg are being developed to help with this.
The View from the Lakehouse
Okay, that’s enough of a trip down memory lane. The technologies we use to manage data have come a long way. Let’s now delve into my specific experience, implementing a Lakehouse at one of our largest clients.
One note first – with a Data Lakehouse, we still had to write ETL, although far fewer ETL steps in than with an EDW or with data marts.
Drilling down to particular examples, our clients implementing Data Lakehouses are using several of our products including Flare, a data integration and decisioning platform optimized for mobile operators, and our Data Fabric that includes a Data Lake as well as a Business Semantics Layer and other open-source and LigaData IP tools. Our client wanted to deploy a standard Telco data model across their business. As you all know, it is not in the nature of unstructured data storage to provide an easy interface to a Telco data model. For us, the solution was to provide a metadata veneer over the data lake. This veneer came to be known to us by its industry name, a Data Lakehouse. We defined the Lakehouse as a data management structure based on cheap storage that can be directly accessed by queries. A Data Lakehouse would also provide analytical RDBMS management capabilities and performance features such as indexing, caching, ACID transactions, data versioning, and the capability for query optimization. Our client, as is the case with most Telco environments, came from an Oracle, Teradata and Microsoft SQLServer background. The idea of having familiar ACID transactions back was and exciting bonus. This environment allowed a fit with their newly purchased Telco data model as well.
The important idea for implementing the Lakehouse was to have the system store data in a low-cost object store (Data Lake) using a standard file format, and implement a transactional metadata veneer on top of the object store. This meta data tells us which objects are part of a table version. This allowed the system to implement management features such as ACID or transactions and versioning within the metadata layer, while keeping the bulk of the data in the low-cost Data Lake. Again, still allowing clients to directly read objects from this object store using a standard file format.
Enabling Machine Learning and AI
Many Machine Learning (ML) libraries, such as those included with Jupyter and Spark MLlib, can already read Data Lake file formats such as Parquet. Therefore, the easiest and fastest way to integrate the ML modules with a Lakehouse is to query the metadata layer to figure out which Parquet files are part of a table and send that info to the ML library.
Of course, savvy companies soon began developing richer data management layers over these systems, including Apache Hive 3 ACID, which tracks which data belongs to which Hive table and version using an OLTP RDBMS and allows operations to update this set transactionally. In recent years, new systems have provided even more capabilities and improved scalability.
Clearly, a Data Lakehouse veneer is easy to implement if a Data Lake already exists. For example, the veneer can convert an existing directory of Parquet files into a Lakehouse table with zero copies by adding a transaction log that starts with an entry that references all the existing files. The veneer or metadata layers are a natural place to implement data quality features. For example, schema constraints ensure that the data added to a table matches its schema. For other constraints on data, client libraries will reject records that violate specified constraints. LigaData and our client understand these features to be useful in improving the quality of Data Lakehouse data.
Finally, the veneer is a natural place to implement security features such as access control and audit logging. For example, a meta data layer can check whether a client is allowed to access a table before granting it credentials to read the raw data in the table from a cloud object store and can reliably log all accesses.
Summary
During the process of deploying Data Lakehouses, we learned a number of important things. We learned that a unified data platform architecture that implements Data Warehousing functionality over open Data Lake file formats can provide competitive performance with today’s Data Warehouse systems. The Lakehouse will help address many of the challenges facing today’s Data Lake users. A key feature that a Lake House Enables is a Standard Telco Data Model, normally constrained to RDBMS storage structures.
As our client has, LigaData believes that the Telco industry is ready to adopt a Lakehouse architecture – particularly given the large amounts of data already in data lakes and the opportunity to simplify enterprise architectures.
If you have any questions or are looking at implementing a similar solution, contact us today.
References and Further Good Reads on on Data Lakehouses:
- Building the Data Lakehouse – Databricks – by Bill Inmon – Free Book
- Lakehouses Prevent Data Swamps, Bill Inmon Says – Datanami Article
- What Is A Data Lakehouse? A Super-Simple Explanation For Anyone – by Bernard Marr – Forbes Article
- The Data Lakehouse Architecture – BizOne by Kildo Alias
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics – by Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia, Databricks, UC Berkeley, Stanford University
- Data Lake or Warehouse? Databricks Offers a Third Way – Datanami Article
Blog by Jaime Charaf, PMO of New Business.


